Le mythe du fichier llms.txt : 10 millions de requêtes IA analysées, 0 lecture (Étude Senthor)
Faut-il installer un fichier llms.txt ? Senthor a analysé 10 millions de visites d'IA. Verdict : aucun bot majeur ne le lit. Découvrez les chiffres exclusifs.
En bref : Faut-il utiliser un fichier llms.txt ?
Non. Le fichier llms.txt, proposé comme nouveau standard pour contrôler les IA, est actuellement ignoré par les principaux LLMs. Une étude de Senthor sur plus de 10 millions de requêtes IA certifiées montre qu'aucun bot majeur (OpenAI, Claude, Google) ne tente de lire ce fichier. C'est une "légende urbaine" technique.
Le Hype du llms.txt
Depuis quelques mois, le fichier llms.txt est présenté comme LA solution miracle pour donner des instructions aux intelligences artificielles. Un peu comme un robots.txt pour le futur, où vous pourriez dire aux IA ce qu'elles peuvent ou ne peuvent pas scraper.
Des dizaines d'articles de blog, de threads Twitter et de discussions sur Hacker News vantent ce nouveau "standard". Certains développeurs l'ont même déjà ajouté à leur site.
C'est beau sur le papier, mais est-ce que les robots le lisent vraiment ?
Chez Senthor, on ne fait pas de suppositions. On a vérifié les logs serveurs. Voici la vérité.
L'Étude Senthor : 10 Millions vs Zéro
Depuis septembre 2025, Senthor analyse le trafic de milliers de sites web pour identifier les bots d'IA. Nous avons une vue privilégiée sur comment les grands modèles (OpenAI, Anthropic, Google, Perplexity) interagissent réellement avec les sites web.
Voici les chiffres :
Traduction : Sur 10 millions de visites confirmées de bots d'IA majeurs, exactement zéro ont tenté de lire le fichier llms.txt. Les 104 requêtes détectées provenaient d'humains curieux ou de petits scrapers non-identifiés, pas des LLMs que vous essayez de contrôler.
La Preuve en Direct
Ces données ont été partagées publiquement par Matt El mouktafi, CTO de Senthor, sur LinkedIn :
Les données brutes partagées par Matt El mouktafi, CTO de Senthor.
Pourquoi ça ne marche pas ?
Il y a deux raisons techniques majeures pour lesquelles le fichier llms.txt est ignoré :
1. Absence de Standard Officiel
OpenAI, Google et Anthropic n'ont jamais officiellement adopté ce standard. Le fichier llms.txt est une invention communautaire qui n'a aucun support des acteurs majeurs.
Ces entreprises suivent (parfois) le robots.txt parce que c'est une convention historique vieille de 30 ans. Mais elles n'ont aucune obligation ni intention de lire les inventions récentes de la communauté.
2. Les IA n'indexent pas les sites
Contrairement aux moteurs de recherche classiques (Google, Bing), les IA ne parcourent pas votre site de manière exhaustive. Ce n'est pas leur métier.
Les assistants IA (ChatGPT, Claude, Perplexity) utilisent des systèmes de recherche existants pour trouver l'information pertinente. Quand un utilisateur pose une question, l'IA interroge un moteur de recherche, identifie la page spécifique qui contient la réponse, et visite uniquement cette page. Le tout en quelques millisecondes.
Elles ne vont pas consulter votre sitemap.xml ou votre llms.txt pour se balader sur votre site jusqu'à trouver l'info. Elles accèdent directement à la page cible via une recherche, extraient le contenu, et repartent.
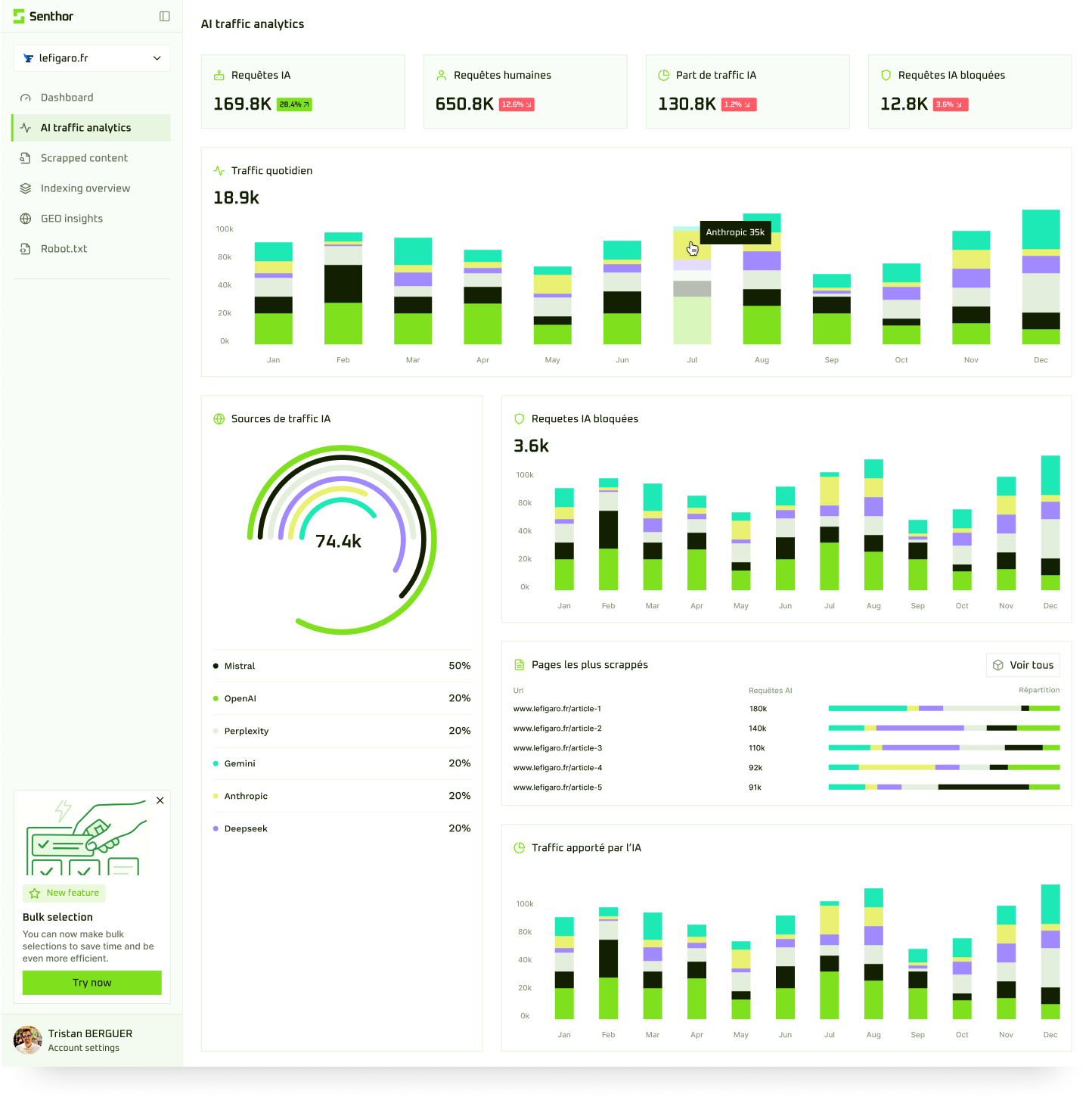
Figure : Analyse du trafic IA sur Senthor - Aucune lecture de llms.txt détectée
Comment contrôler vraiment les IA en 2026 ?
Arrêtez de croire aux solutions magiques. Voici ce qui fonctionne réellement :
✅ Conseil 1 : Gardez votre robots.txt
C'est le "minimum syndical". Certains bots le respectent encore (pas tous, mais c'est mieux que rien). Comme nous l'avons vu dans notre article sur pourquoi robots.txt ne suffit plus à l'ère de l'IA, ce n'est pas une protection absolue, mais ça reste la base.
✅ Conseil 2 : Détection Server-Side
Puisque les IA ne demandent pas la permission (ne lisent pas le llms.txt), il faut les détecter Server-Side. Il faut analyser leur signature, leur User-Agent, leur IP et leur comportement pour les identifier avant qu'elles ne scrapent le contenu.
C'est exactement ce que fait Senthor : identifier en temps réel les bots d'IA, les bloquer si vous le souhaitez, ou mesurer leur impact. Comme nous l'avons montré dans notre analyse du Dark AI Traffic dans Google Analytics, la détection server-side est la seule méthode fiable.
✅ Conseil 3 : Optimisez pour les réponses, pas pour les fichiers
Si vous voulez que les IA citent votre contenu correctement, optimisez votre contenu structuré (GEO - Generative Engine Optimization). Utilisez des outils de visibilité comme Atyla pour vérifier comment les IA comprennent votre site, pas des fichiers textes invisibles que personne ne lit.
Conclusion : Arrêtez de naviguer à l'aveugle
Le fichier llms.txt est une belle idée en théorie. Mais les données ne mentent pas.
Sur 10 millions de requêtes d'IA certifiées, zéro bot majeur n'a tenté de le lire. C'est un fait, pas une opinion.
Si vous voulez vraiment contrôler comment les IA interagissent avec votre contenu, basez-vous sur la réalité technique, pas sur le hype communautaire.
Vérifiez si les IA visitent vraiment votre site
Arrêtez les suppositions. Analysez le trafic IA réel avec des données précises.
Auditez votre trafic IA gratuitementAucune carte de crédit requise • Installation en 2 min
Protégez votre contenu dès aujourd'hui
Monétisez votre contenu face aux IA avec Senthor.